上周v2ex发了个帖子火了,顺便观察了一下v友们关心的话题
目录
前言 #
上周,我在v2ex上发表了一篇文章,题目是《聊聊我在一个月抖音小红书粉丝累积到3万最后不再维护的事》。
帖子在v站火了,差不多连续四五天在节点榜首,也有不少人点赞收藏。我很少在v站上发帖,我记得再上一篇还是在2019年8月。 在v站发帖是因为经常看到做独立开发的小伙伴在v站推广APP,来积累种子用户。
所以我想着通过爬虫爬取了v站上所有的帖子和评论,来对其做一些研究。

可能有些网友不知道,v站是什么,来看下维基百科。

如何分析 #
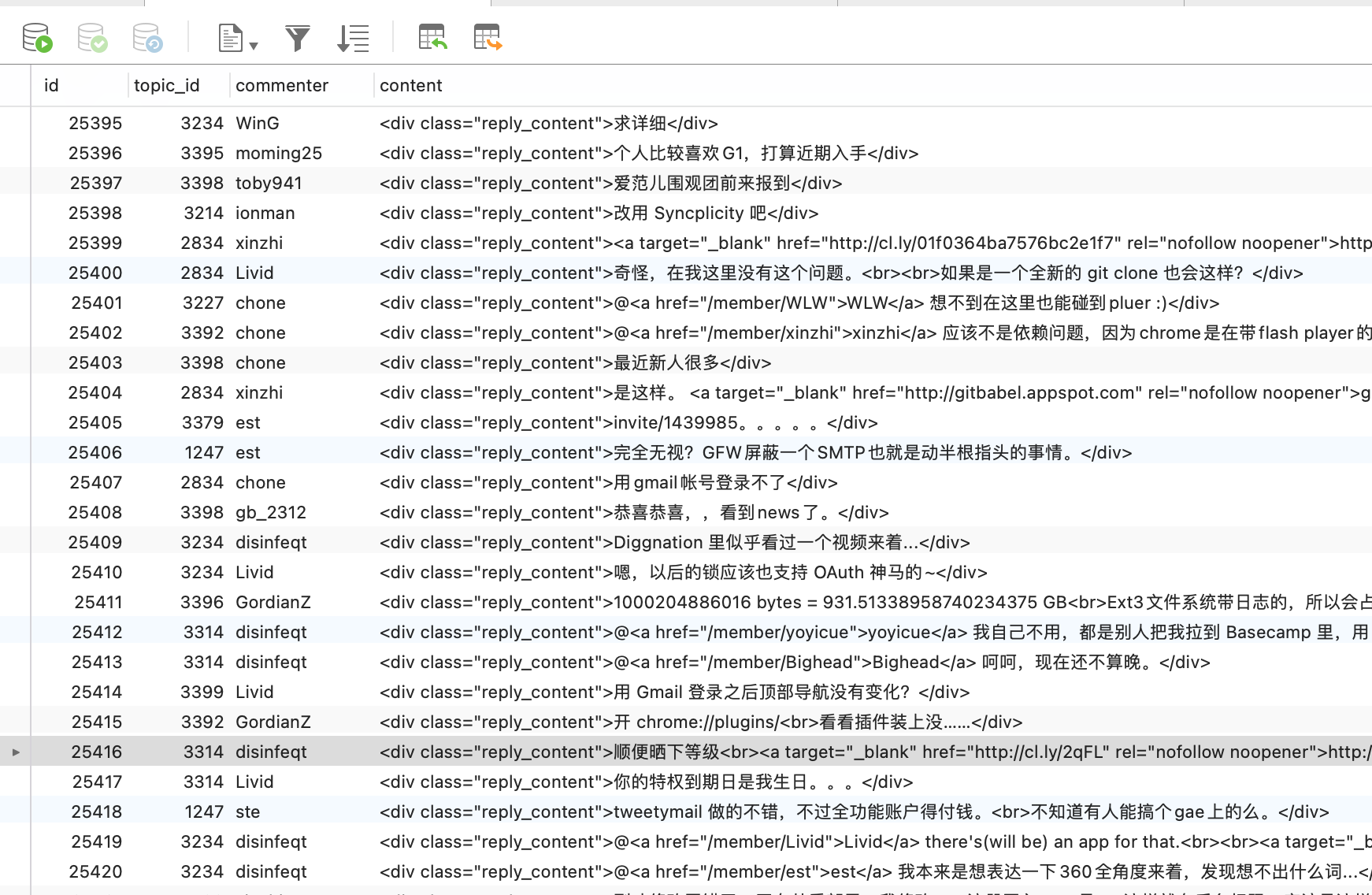
我的计划很简单,就是爬取v站所有的内容。要想写这样一个爬虫其实也比较花时间,我在Github调研了很多爬虫脚本和框架,在此要感谢为爱发电的开源力量。我使用了名为
v2ex_scrapy的爬虫脚本进行了内容收集,用起来非常舒服,非常感谢作者。

同时我尝试了使用 Chatgpt 最新的 gpts 功能,尝试把爬下来的整个 sqlite 作为 gpts 的数据库,想让gpts来为我做数据分析的业务。
jieba 和 wordclound 开始敲代码。
词云图 #
先来看看v友们平时都聊的话题。

从图上可以看出排名靠前的词都是和程序员有关的。
上一张词图是所有帖子的,现在把时间锁定到新冠爆发半年后开始(经济开始下行)。

迫于大多流行在二手交易节点。二、Mac苹果系始终是这群人的焦点。
最后这张词云图把时间锁定在了去年十一月之后,chatgpt横空出世。

每月新增 #
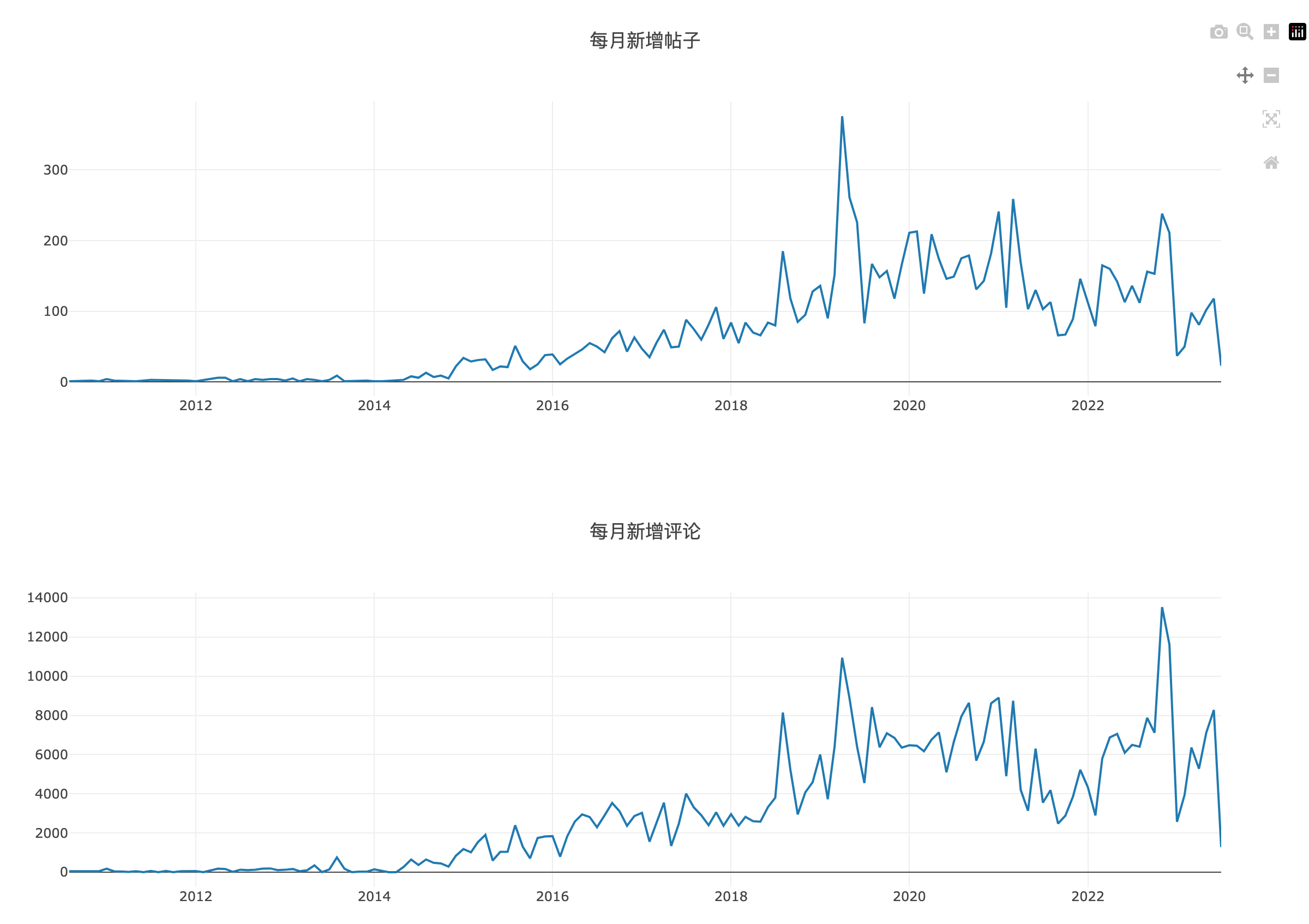
接下来我们看一下每月新增帖子和评论数量。
按小时聚合 #
另外,我统计了所有的帖子和回复评论的发布时间段,有个很有趣的现象。
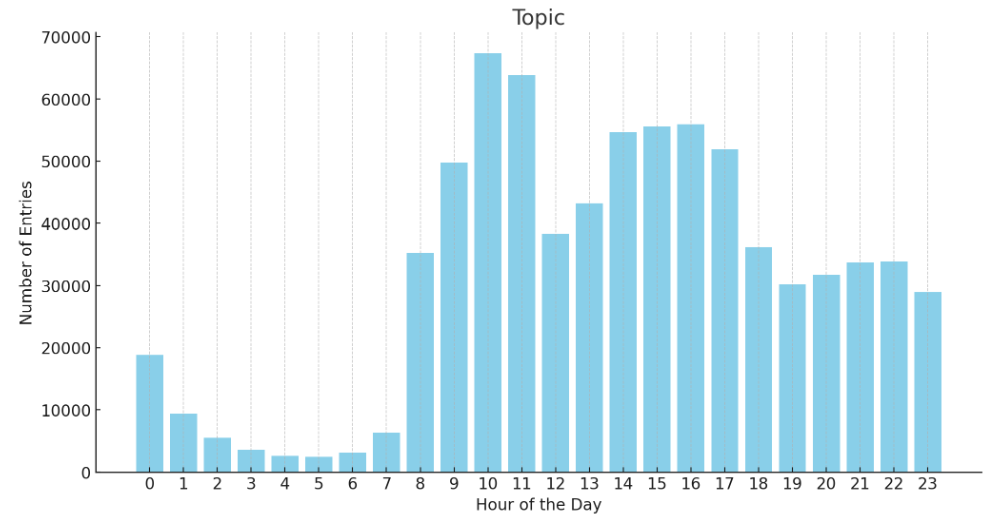
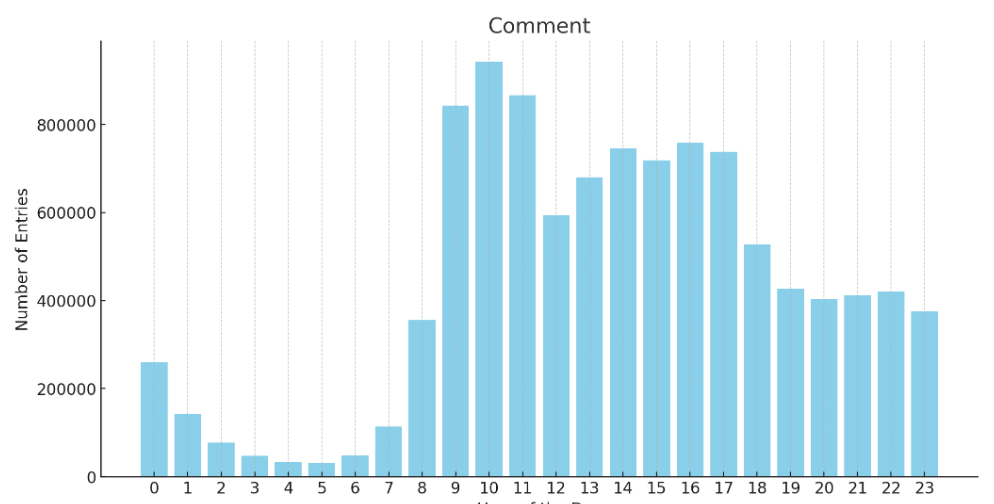
有人会说很多都是周末数据,其实我已经把周六周日的数据给过滤了。
澄清一下,这些数据只是相对来说逛论坛的分析,不代表所有人都在这些时间点摸鱼,这是所有数据的总和。
前十数据 #
最后,看看所有帖子排名靠前的都是哪些。
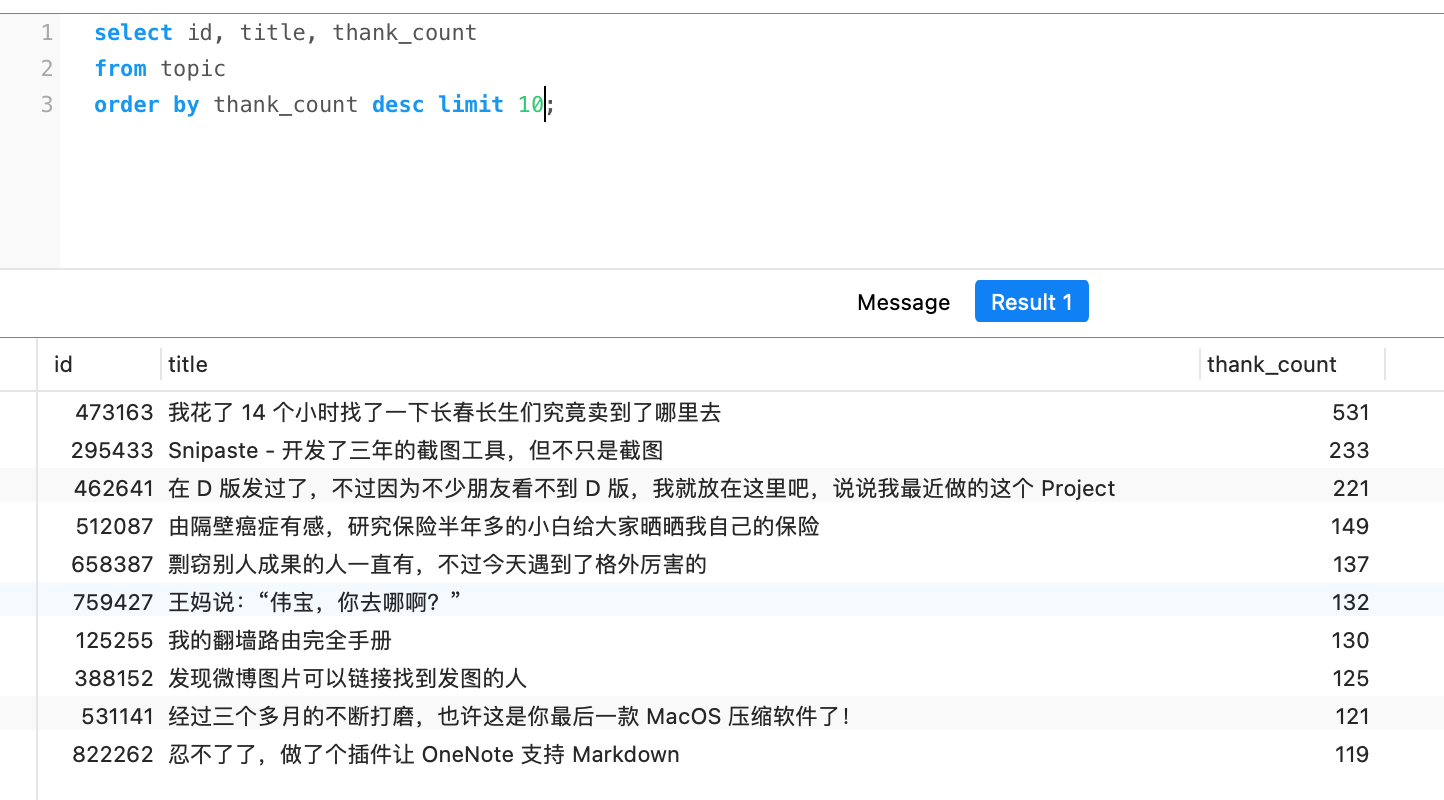
感谢最多的前十 #
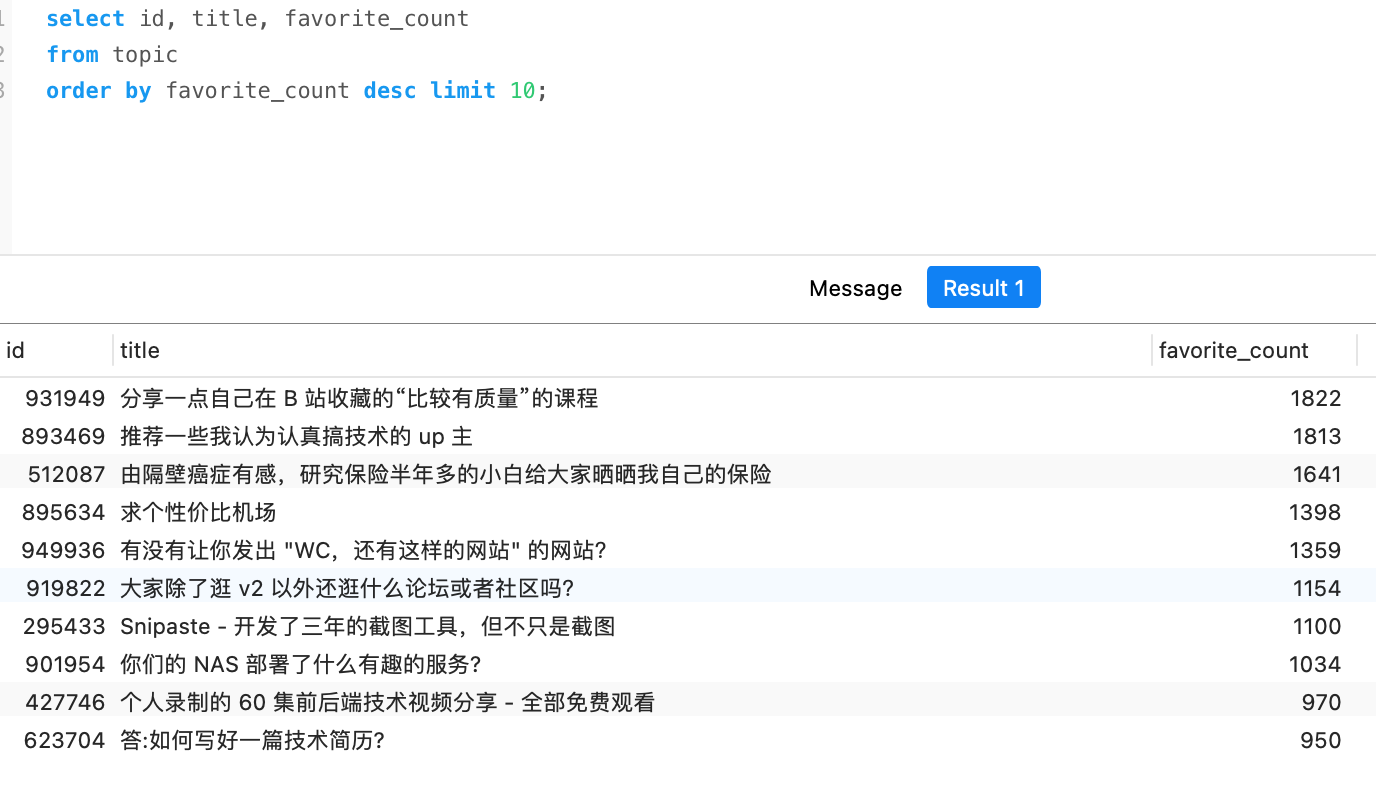
收藏最多的前十 #
点击最多的前十 #
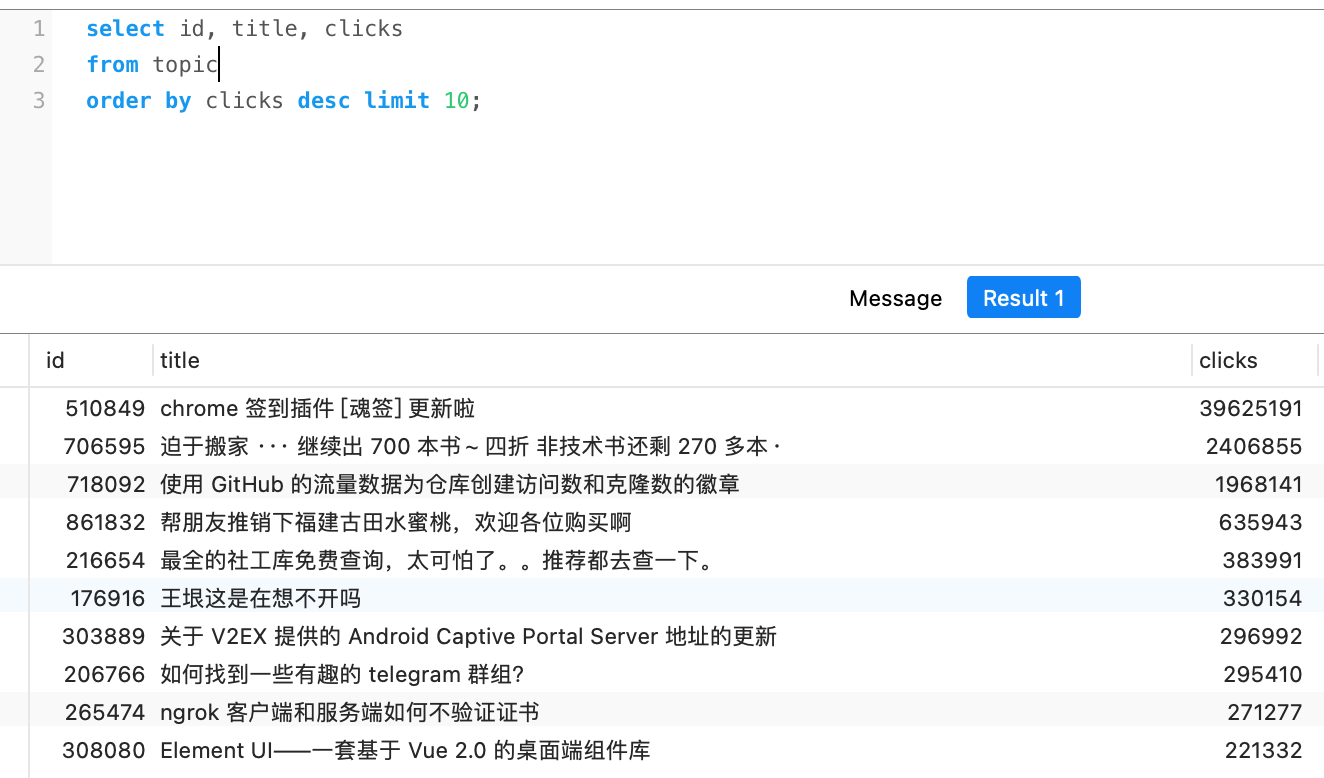
投票最多的前十 #
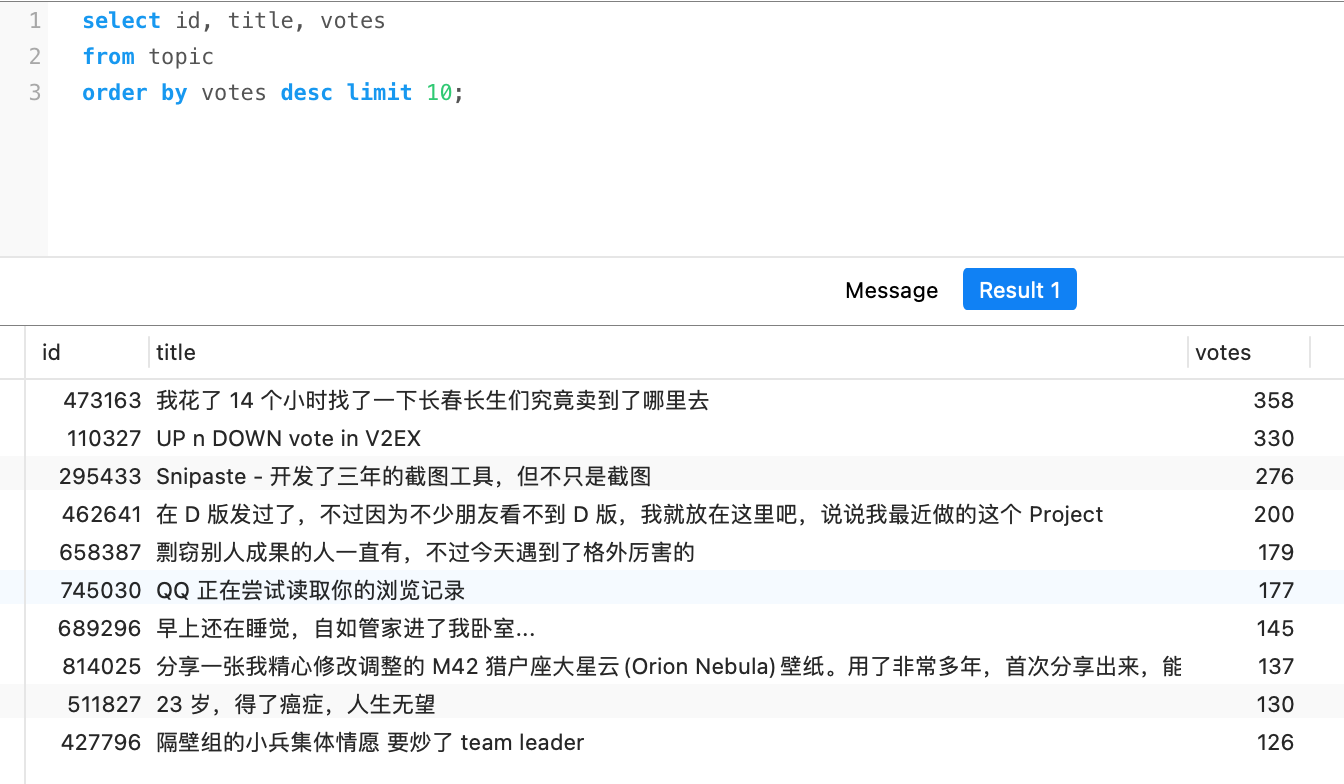
总结 #
总的来说,v2ex 还是很有意思的一个社区,在这里包罗了所有程序员、极客,工作和生活上的有趣的内容。也是这个群里摸鱼的一个好去处,当然在这里你也能看到一些,学到一些。
我也常常在v站潜水。最近发帖才知道,原来帖子发出后有一个保护期超过这个时间后,帖子将无法修改也无法删除,所以在这里发言还是要慎重一些。
一些 Tips:
本文的数据来源都是 v2ex_scrapy开源项目中获得。
由于个人电脑原因我爬取的时间经常在半夜中断,时间也比较长最后选择之后了作者之前爬取更新至2023-7-22为止的数据。我用自己写的脚本对数据进行二次加工进行最终分析统计。
部分图表是把脚本跑完的数据传给chatgpt,最终由gpt生成。
